A single fault in a traditional Programmable Logic Controller (PLC) can bring production to a standstill.
This may lead to a considerable financial loss and posing serious safety hazards. To prevent these consequences, many industries rely on PLC redundancy.
An approach that introduces additional components to guarantee system reliability and uptime.
With a standby system ready to automatically assume control, redundant PLCs serve as a dependable safeguard in environments where continuous performance is essential.
This article introduces redundancy in PLC systems, by explaining what it is, how does it function, types, its core components and finally the factors to consider when implementing it.
The Purpose of PLC Redundancy
The main objective of PLC redundancy is to remove single points of failure and maintain continuous system availability.
In a non-redundant configuration, a failure in the PLC or one of its components halts the entire process. This scenario can lead to multiple problems:
Safety hazards
A malfunction could result in uncontrolled motion, chemical leaks, or other hazardous situations.
Downtime
Unexpected production stops often cause significant financial losses due to idle equipment and lost productivity.
Data loss
Critical process data may be lost during an outage, affecting product quality and traceability.
Equipment damage
Abrupt shutdowns may harm costly machines, increasing maintenance and repair expenses.
A redundant PLC setup ensures that operations continue seamlessly even when a main controller or hardware component fails, providing a reliable backup path to keep production stable.
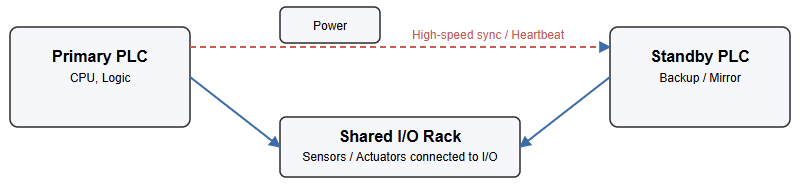
How Does Redundancy Work
A redundant PLC system can switch control automatically when a failure occurs. The main and standby controllers stay synchronized in real time. They share memory states, logic, and I/O data. This keeps the backup ready to take control at any moment.
A heartbeat signal monitors the health of both PLCs. Each one checks for hardware, communication, or power problems. When the standby detects a missing heartbeat or a fault, it activates the failover process.
The backup controller immediately takes over. It handles inputs, outputs, and communication without delay. The failed PLC is isolated, and an alarm alerts the maintenance team.
Repairs can be done while the system keeps running. After the problem is fixed, the controller is synchronized again and returned to standby mode. This process keeps downtime low and ensures safe, reliable operation.
Main Types of PLC Redundancy
PLC redundancy can be implemented at different levels, depending on the required reliability and budget constraints. The three principal categories are cold standby, warm standby, and hot standby.
Cold Standby Redundancy
Cold standby represents the simplest and most affordable form of redundancy, where a backup system remains powered off until needed.
Operation
When the primary PLC fails, the operator is notified and must manually start the backup controller. This includes powering it on, initializing it, and linking it to the input/output (I/O) network.
Response time
Because human intervention is required, recovery time is relatively long, and a brief process interruption is inevitable.
Best suited for
non-critical systems where downtime is acceptable and failure costs are minimal—for instance, a basic conveyor or material-handling setup.
Illustration
A diagram could display an active PLC with a secondary, powered-down unit, and a manual switch or connection indicating the operator’s role in activation.

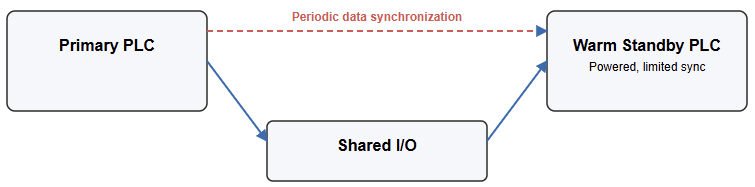
Warm Standby Redundancy
Warm standby systems provide quicker response times, as the backup PLC operates in a semi-active, monitoring mode.
Operation
Two identical PLCs run the same logic. The primary executes control functions, while the secondary monitors system health through a continuous “heartbeat” signal. If the primary fails, the backup quickly assumes control.
Response time
The switchover occurs faster than cold standby but might still cause a slight interruption in operation.
Best suited for
Processes that can tolerate a brief pause but still demand a rapid recovery—offering a middle ground between performance and cost.
Illustration
A figure could depict both PLCs powered and connected through a communication link, sharing I/O, with a heartbeat signal representing constant monitoring.
Hot Standby Redundancy
Hot standby delivers the highest reliability and nearly instantaneous failover, making it ideal for mission-critical operations.
Operation
Both PLCs are fully powered and synchronized, with each connected to the I/O network.
The primary runs the control logic while the secondary mirrors every operation in real time through a dedicated high-speed link.
If the main controller fails, the backup takes over within milliseconds, ensuring an uninterrupted transition.
Response time
Failover occurs within a single PLC scan cycle, effectively “bumpless.”
Best suited for
Critical processes where downtime is unacceptable—such as energy generation, oil and gas facilities, and pharmaceutical manufacturing lines.
Illustration
The diagram would display two synchronized PLCs linked by a high-speed channel, both connected to the same I/O, with automatic switching shown between the “active” and “standby” units.

Core Components in Redundant Systems
True redundancy involves more than just duplicating CPUs. To eliminate single points of failure, other key hardware components must also be replicated.
Redundant CPUs form the foundation of this approach. A main and a backup processor are connected through high-speed synchronization, constantly mirroring data to maintain identical operating states.
Redundant power supplies ensure power continuity even if one unit fails. Many systems support hot-swapping, allowing faulty units to be replaced without shutting down the system.
Input and output modules can also be duplicated for maximum dependability. In critical applications, a two-out-of-three (2oo3) logic configuration may be used, where three sensors monitor the same parameter and the two consistent readings are accepted as valid.
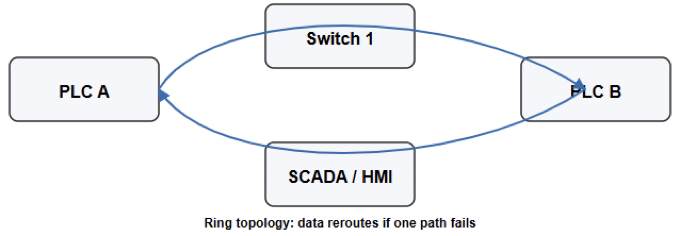
Network redundancy is equally important. Fail-safe communication is achieved through ring topologies or redundant Ethernet paths, which allow data to be rerouted in case of cable or port failures.
This guarantees uninterrupted communication between PLCs, I/O modules, and supervisory systems such as SCADA.
Factors to Evaluate When Implementing Redundancy
Redundancy improves reliability, but it is not always the right solution. Each system must be evaluated carefully before implementation.
Cost and benefit must be balanced. Adding redundancy increases both expense and complexity.
The investment should make sense when compared to the possible financial loss or safety risk caused by a failure.
The criticality of the application is another key factor. The level of redundancy should match how important the process is.
A small machine might use a cold standby setup, while a power distribution system may require hot standby operation.
PLC platform support also matters. Not all PLCs support redundancy by default. Some vendors, such as Siemens with the S7-1500 R/H series and Rockwell Automation with ControlLogix, offer built-in options. Others may need custom programming or external hardware.
System complexity should not be underestimated. Redundant systems are more advanced and require trained engineers.
They must know how to manage diagnostics, firmware updates, and synchronized programming.
Software reliability is another consideration. Redundancy protects against hardware faults but not programming errors. Both controllers run the same code, so any logic flaw will affect them equally.
Maintenance planning is essential. Reliable operation depends on regular testing, firmware checks, and inspection of synchronization links and power modules. Consistent maintenance ensures that redundancy continues to perform as intended.
Key Takeaways: Redundancy in PLC systems
In industrial automation, PLC redundancy serves as a powerful method for achieving high system availability, minimizing downtime, and enhancing operational safety.
By duplicating key hardware components and using intelligent failover strategies, industries can protect valuable assets, maintain consistent production, and avoid costly shutdowns.
While redundancy introduces additional expense and design complexity, selecting the correct level from cost-effective cold standby setups to advanced hot standby systems ensures that each application achieves the right balance between reliability and affordability.
Ultimately, a successful redundant PLC implementation requires a careful evaluation of process criticality, vendor capabilities, and maintenance resources.
When properly designed and maintained, a redundant PLC architecture offers not only continuous operation but also long-term confidence in the stability and resilience of industrial control systems.
FAQ: Redundancy in PLC systems
What is PLC redundancy and why is it used?
PLC redundancy means duplicating controllers (and often other components) so a backup can take control automatically if the primary fails.
It’s used to eliminate single points of failure, increase availability, reduce downtime, protect safety, and preserve process data.
What are the common redundancy types (cold, warm, hot)?
- Cold standby: backup is powered off and requires manual startup — low cost, long recovery time.
- Warm standby: backup is powered and partially synchronized (shadow mode) — faster switchover with a small glitch possible.
- Hot standby: backup is fully synchronized and can take over virtually instantly (bumpless) — highest availability and cost.
Which components are typically duplicated in a redundant PLC architecture?
CPU/controllers, power supplies, I/O modules (or I/O racks), and communication/network paths are commonly duplicated.
Some critical systems also use voting schemes (e.g., 2oo3 sensors) or redundant HMI/SCADA paths.
Replicating the whole control chain is necessary to remove all single points of failure. (isa.org)
How does the failover (takeover) process normally work?
Primary and standby controllers continuously synchronize state and exchange a heartbeat.
If the standby detects loss of heartbeat or a fault, it runs a failover routine, assumes outputs and communications, logs the error and raises alarms often within milliseconds for hot systems.
Does redundancy protect against software bugs?
No, hardware redundancy protects against hardware/power/network faults, but if the control program itself has a logic bug, both primary and standby will run the same code and will likely fail the same way.
Which vendors provide built-in redundancy support?
Major PLC vendors provide redundancy solutions e.g., Siemens (S7-1500 R/H and Soft Redundancy docs), Rockwell/Allen-Bradley (ControlLogix redundancy manuals), Schneider and others have platform-specific options.
Choose a vendor solution when possible because vendor-tested implementations simplify configuration and support.
How do I choose between cold/warm/hot redundancy for my system?
Based on: process criticality (safety/continuous operation), acceptable downtime and data loss, budget, and vendor/platform support.
Cold for low-criticality and low-cost; warm for moderate needs; hot for mission-critical or safety-sensitive processes. Also consider network and I/O redundancy, not just CPUs.
What additional network strategies are needed for redundancy?
Use redundant network topologies (ring, dual-homing, redundant switches) and deterministic industrial protocols; ensure SCADA/HMI paths are duplicated and isolate machine networks from enterprise networks.
Proper VLANs and managed switches with rapid spanning or PRP/HSR-like schemes are often used.
What are common pitfalls when implementing PLC redundancy?
- Partial redundancy (only CPUs duplicated while I/O or network remains single-point) — gives false confidence.
- Ignoring synchronization/state windows (e.g., non-identical data areas can cause failover issues).
- Insufficient testing and maintenance procedures.
- Assuming redundancy solves software/logic errors.
- Vendor compatibility and version mismatches.
How should redundancy be tested and maintained?
Establish scheduled failover tests, monitor heartbeat and diagnostic logs, keep firmware/software versions synchronized, train maintenance staff, and document procedures for component replacement and reintegration. Use vendor-recommended test steps for safe testing in production.
Are there cost-effective redundancy options for small systems?
Yes. For smaller installations, partial redundancy (redundant power supplies, mirrored critical I/O, UPS, redundant network links) or pragmatic approaches like hot-spare PLCs on standby can provide meaningful improvements at lower cost than full hot-hot systems. Evaluate ROI vs downtime risk.
What documentation or standards should I consult?
Vendor user manuals and redundancy guides (e.g., Siemens, Rockwell), ISA/IEC guidance on high availability and fail-safe design, and industry best-practice articles.
Vendor application notes often include platform-specific limits and required configuration steps.
